Transfer Data from Amazon S3 to Redshift
1. Introduction
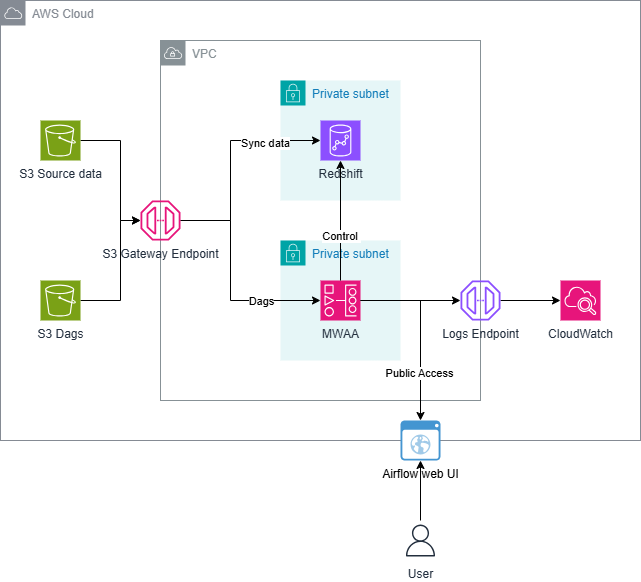
In this module, we will build an ETL pipeline for a database hosted on Redshift. We’ll load data from S3 to staging tables on Redshift and execute SQL to transform data to another table in Star Schema by MWAA
Their analytics team to continue finding insights into what songs their users are listening to.
Source data
Dataset stored in S3, the udacity-dend bucket is situated in the us-west-2 region:
- Song data:
s3://udacity-dend/song_data - Log data:
s3://udacity-dend/log_data
To properly read log data s3://udacity-dend/log_data, you’ll need the following metadata file:
- Log metadata:
s3://udacity-dend/log_json_path.json
Data model
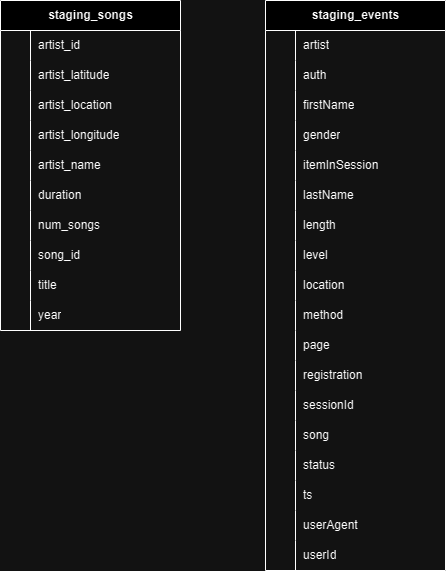
Staging tables
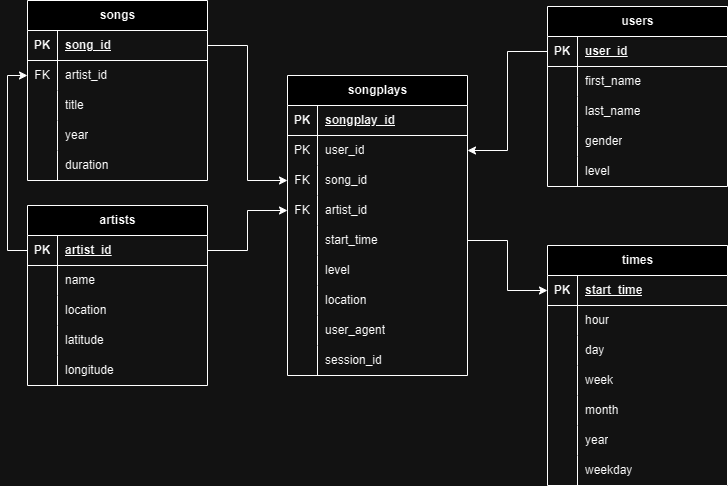
Star schema tables
From song and event dataset, we’ll create a star schema optimized for queries on song play analysis. This following tables:
2. Prepare the environment
Create Environment MWAA
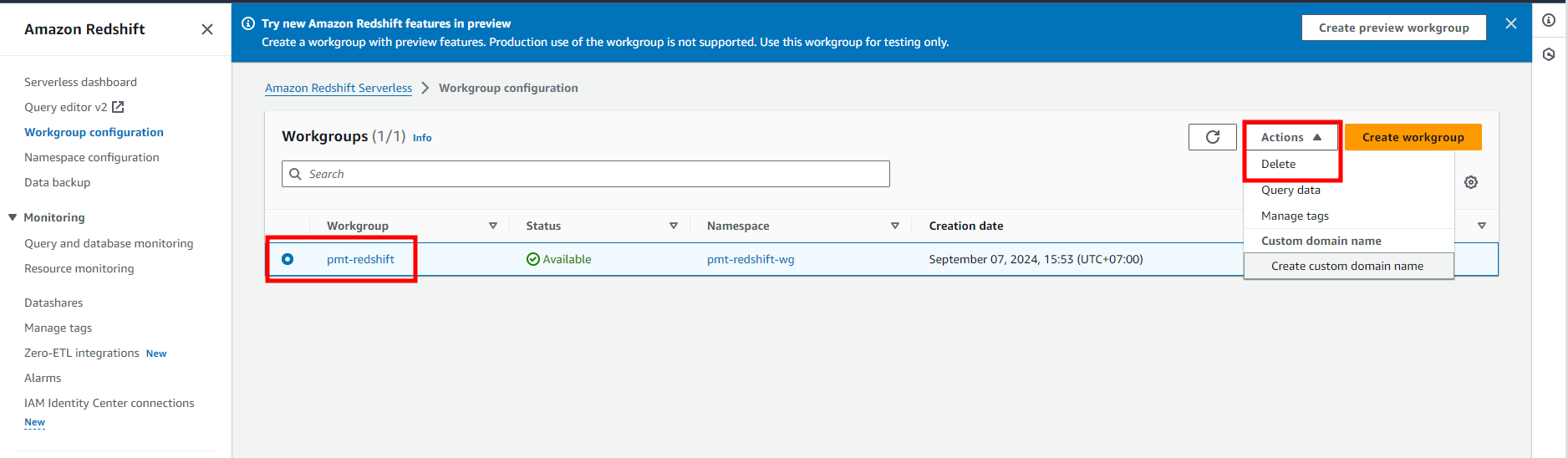
Create Redshift database
- Access Redshift
- Choose Create workgroup
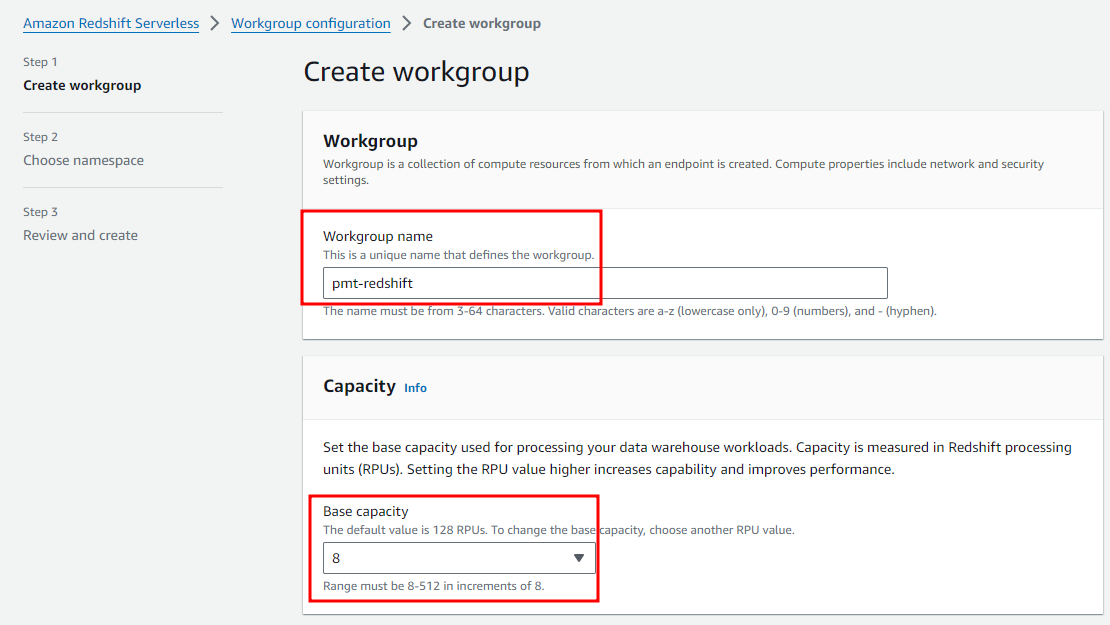
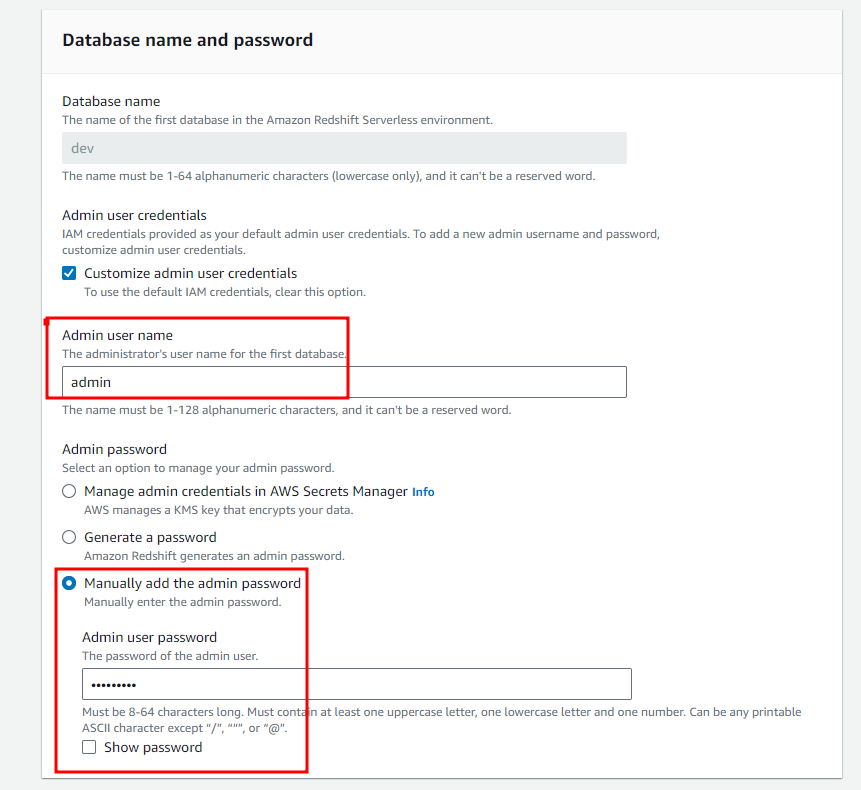
- Choose Custom credential for your database
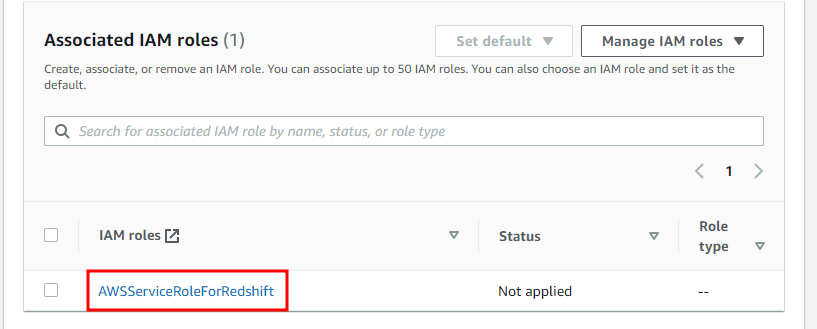
- Choose IAM role for your database
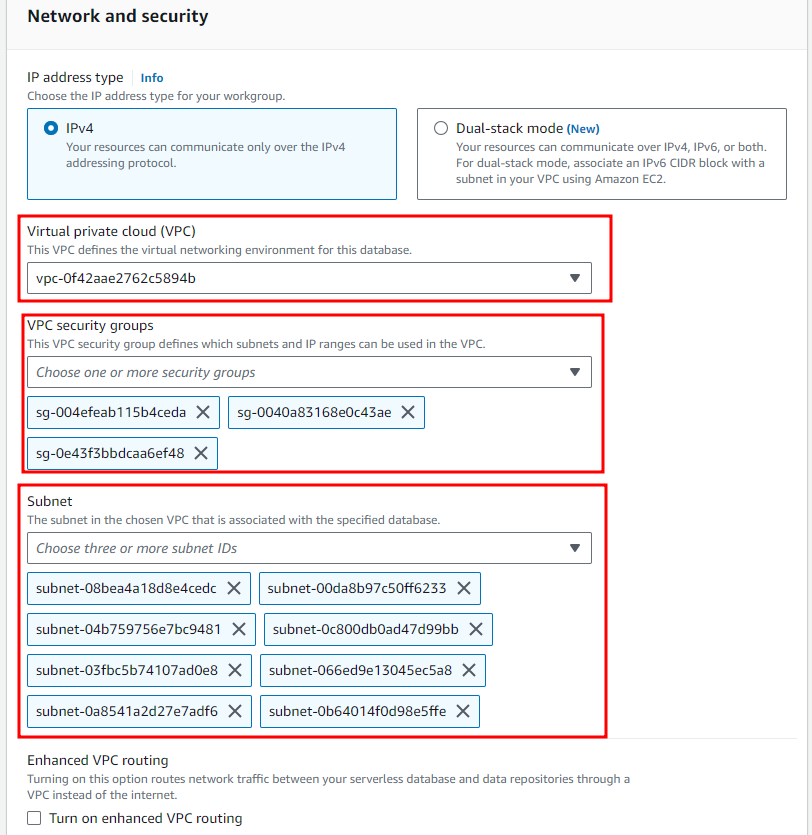
- Choose VPC for your database
- Review and choose Create
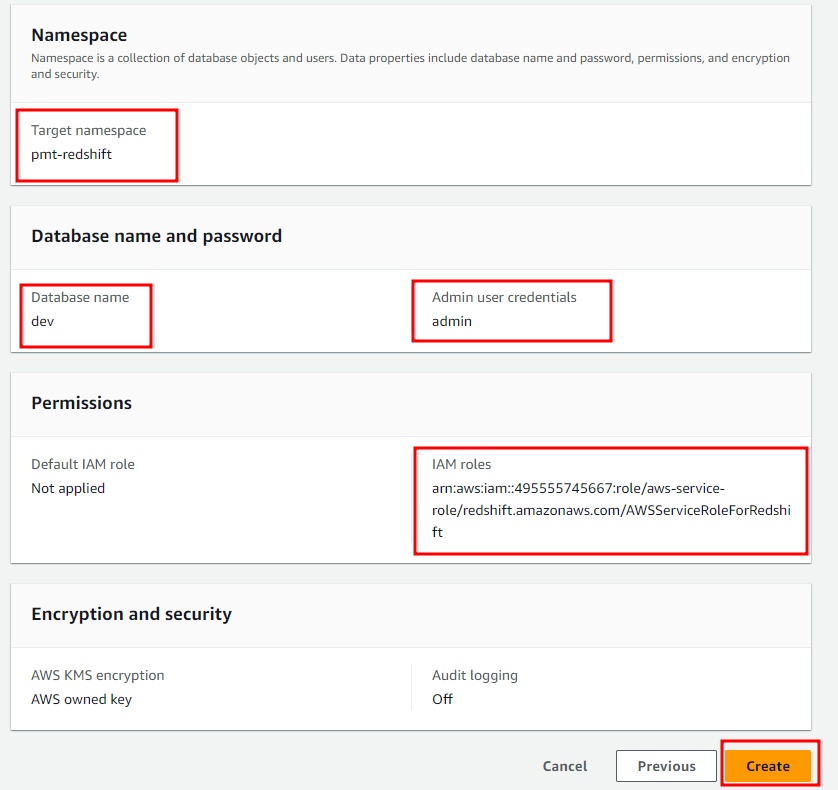
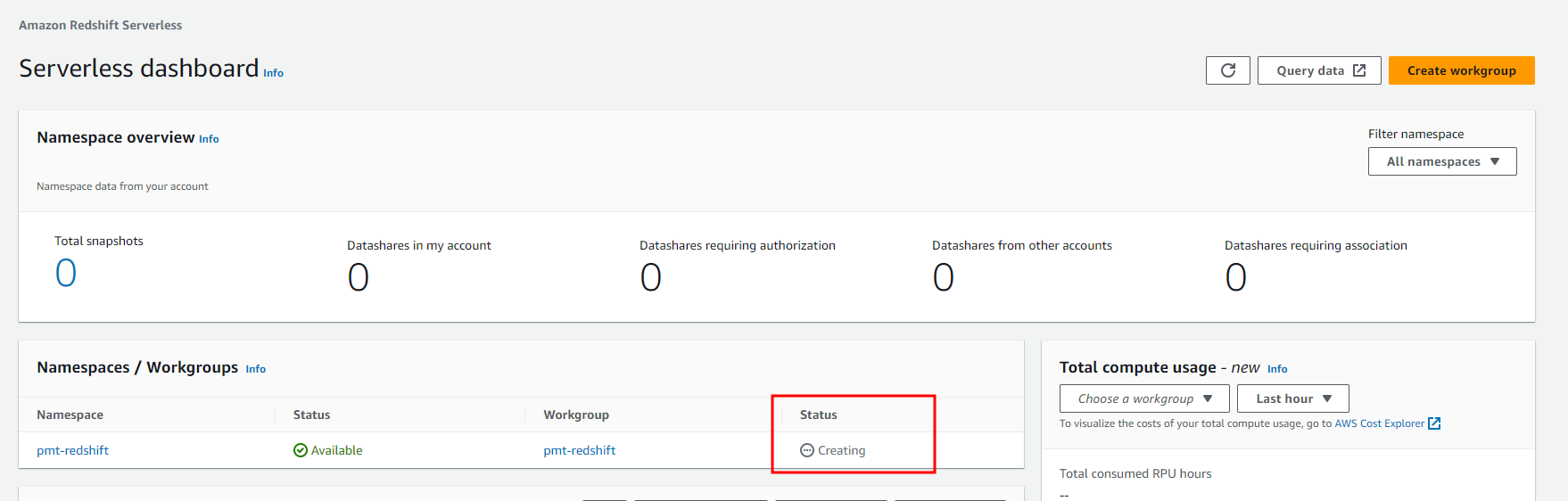
- Access Redshift UI with created user
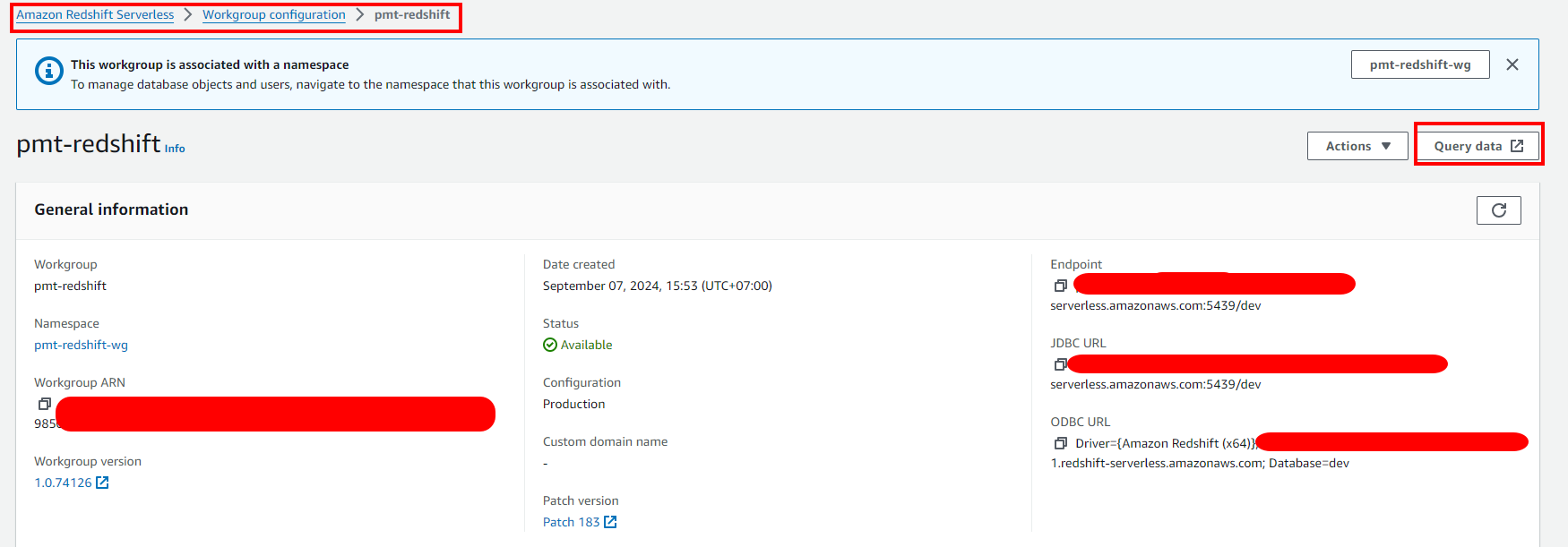
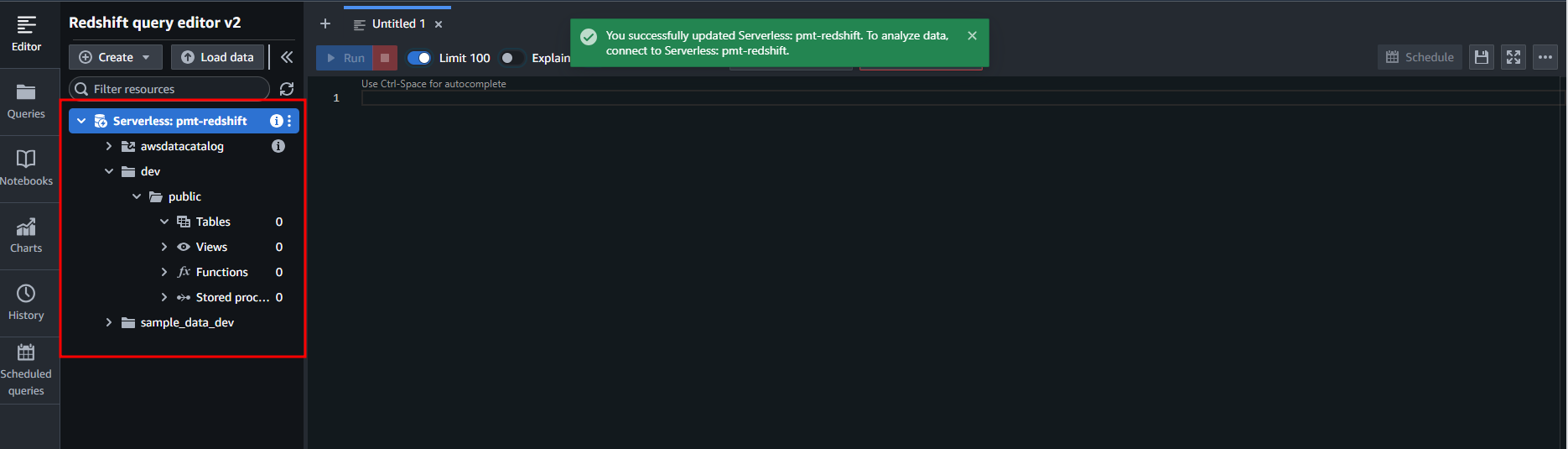
- Download create_tables.sql and run it in Redshift
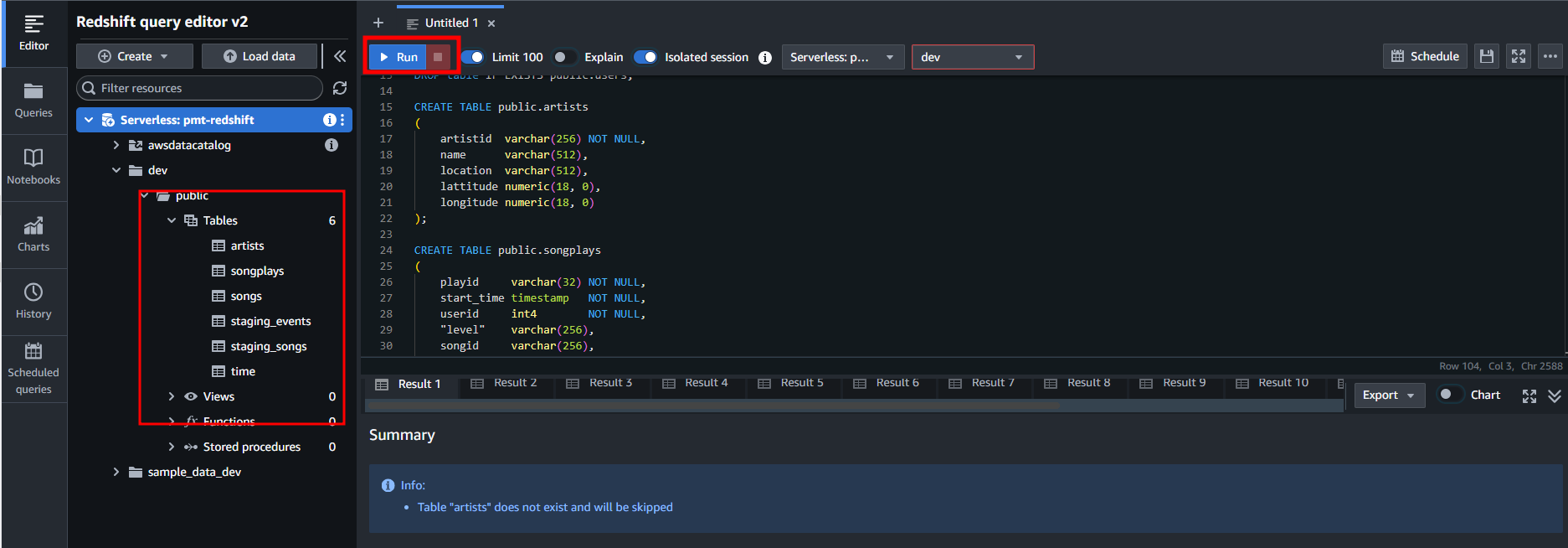
Create IAM role with permission access S3
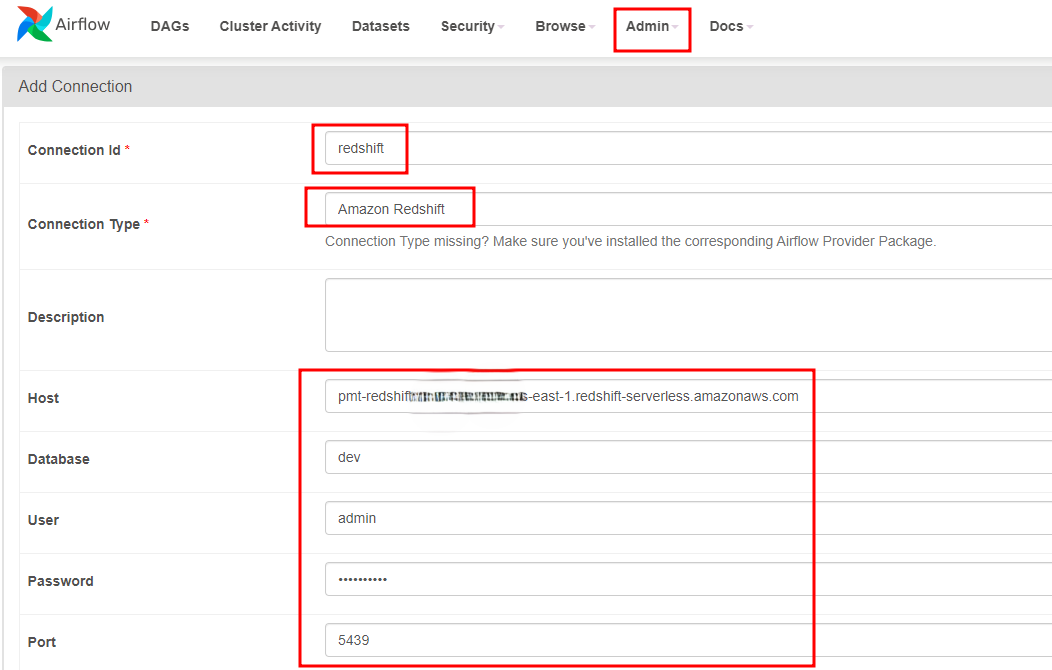
Add connection to Redshift in MWAA
Access Airflow UI
Add Connection
Access Admin/Connection add connection to Redshift

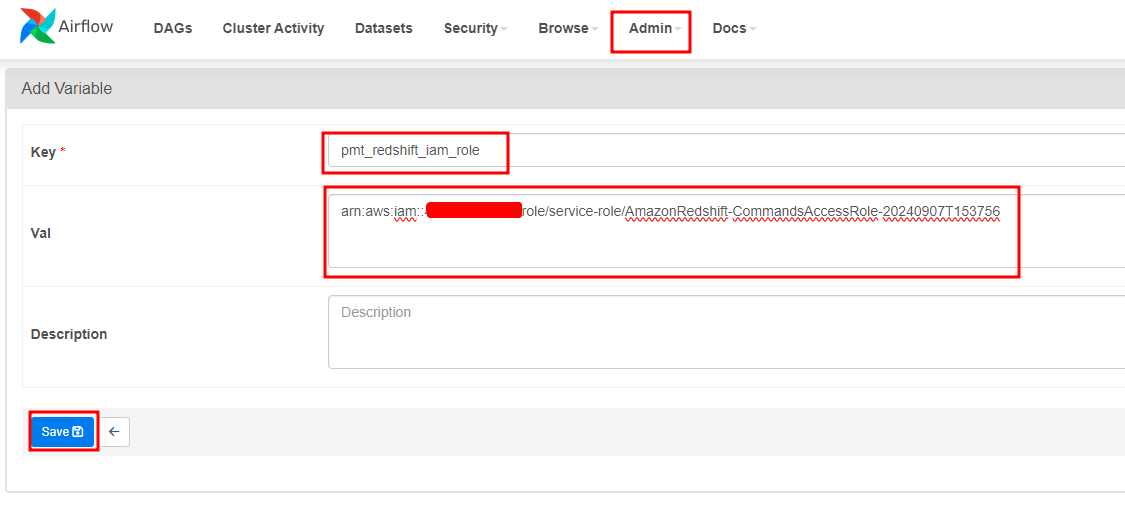
Add Variable
Access Admin/Variable add Iam role Redshift use to access S3
3. Create Dag
In the DAG, add default parameters according to these guidelines
- The DAG does not have dependencies on past runs
- On failure, the task are retried 3 times
- Retries happen every 5 minutes
- Catchup is turned off
- Do not email on retry
default_args = {
'owner': 'pmt',
'start_date': pendulum.now(),
'depends_on_past': False,
'retries': 0,
'retry_delay': timedelta(minutes=5),
'catchup': False,
}
@dag(
default_args=default_args,
description='Load and transform data in Redshift with Airflow',
schedule_interval='@hourly'
)
In addition, configure the task dependencies so that after the dependencies are set, the graph view follows the flow shown in the image below.
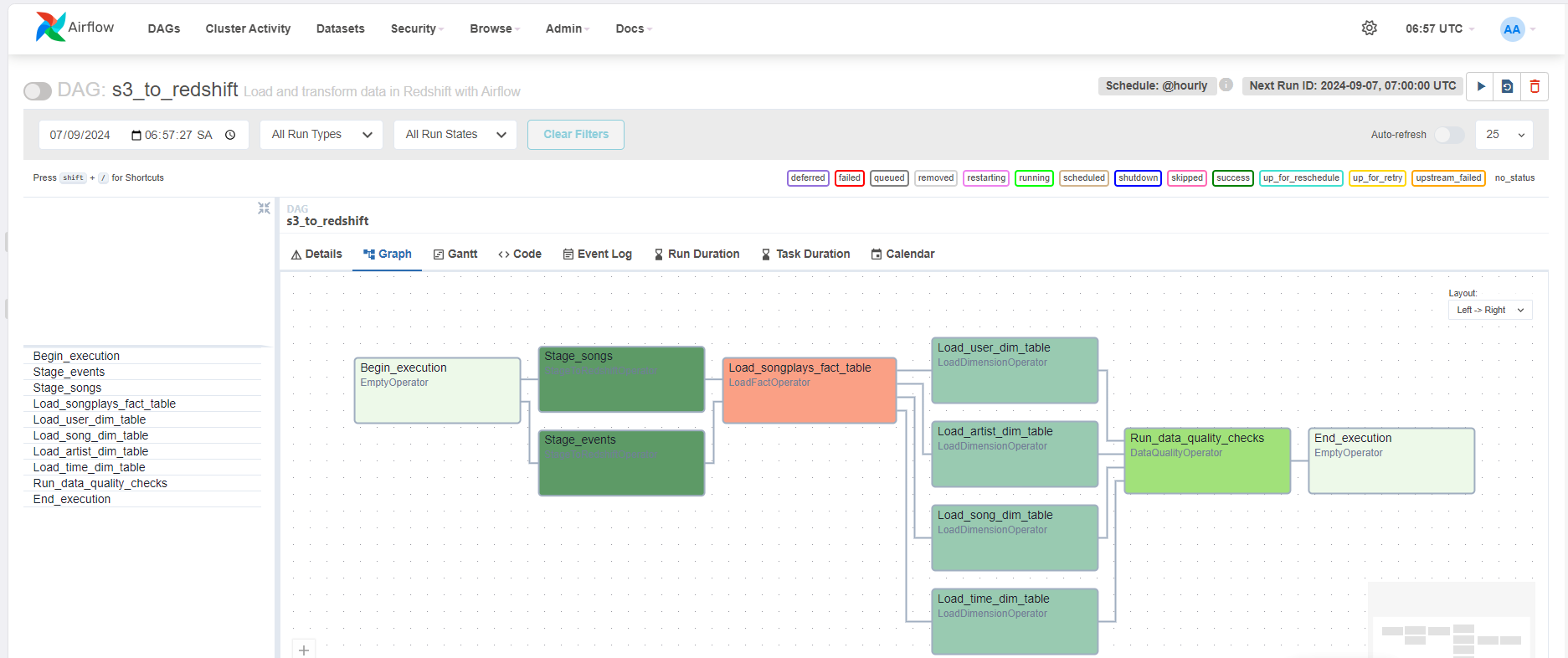
start_operator >> [stage_songs_to_redshift, stage_events_to_redshift] >> load_songplays_table
load_songplays_table >> [load_song_dimension_table,
load_user_dimension_table,
load_artist_dimension_table,
load_time_dimension_table] >> run_quality_checks >> end_operator
Create custom Operator
To complete the project, you need to build four different operators in a
plugins.zip that will stage the data, transform the data, and
run checks on data quality.
Remember to utilize Airflow’s built-in functionalities as connections and hooks as much as possible and let Airflow do all the heavy-lifting when it is possible.
All of the operators and task instances will run SQL statements against the Redshift database. However, using parameters wisely will allow you to build flexible, reusable, and configurable operators you can later apply to many kinds of data pipelines with Redshift and with other databases.
Stage Operator
The stage operator is expected to be able to load any JSON formatted files from S3 to Amazon Redshift. The operator creates and runs a SQL COPY statement based on the parameters provided. The operator’s parameters should specify where in S3 the file is loaded and what is the target table.
The parameters should be used to distinguish between JSON file. Another important requirement of the stage operator is containing a templated field that allows it to load timestamped files from S3 based on the execution time and run backfills.
class StageToRedshiftOperator(BaseOperator):
ui_color = '#358140'
s3_copy = """
copy {table_name} from {s3_part}
iam_role {iam_role}
region 'us-west-2'
format as json {opt}
"""
@apply_defaults
def __init__(self,
redshift_conn_id="",
table="",
s3_part="",
iam_role="",
json_opt="'auto'",
append=False,
*args, **kwargs):
super(StageToRedshiftOperator, self).__init__(*args, **kwargs)
self.redshift_conn_id = redshift_conn_id
self.s3_part = s3_part
self.iam_role = iam_role
self.json_opt = json_opt
self.redshift = PostgresHook(postgres_conn_id=self.redshift_conn_id)
self.table_name = table
self.append = append
def execute(self, context):
if not self.append:
self.log.info("Clearing data from destination Redshift table")
self.redshift.run("DELETE FROM {}".format(self.table_name))
self.log.info("Copying data from S3 to Redshift")
self.redshift.run(
self.s3_copy.format(
table_name=self.table_name,
s3_part=self.s3_part,
iam_role=self.iam_role,
opt=self.json_opt
)
)
Fact and Dimension Operators
With dimension and fact operators, you can utilize the provided SQL helper class to run data transformations. Most of the logic is within the SQL transformations and the operator is expected to take as input a SQL statement and target database on which to run the query against. You can also define a target table that will contain the results of the transformation.
Dimension loads are often done with the truncate-insert pattern where the target table is emptied before the load. Thus, you could also have a parameter that allows switching between insert modes when loading dimensions. Fact tables are usually so massive that they should only allow append type functionality.
class LoadFactOperator(BaseOperator):
ui_color = '#F98866'
@apply_defaults
def __init__(self,
redshift_conn_id="",
sql="",
table="",
append=False,
*args, **kwargs):
super(LoadFactOperator, self).__init__(*args, **kwargs)
self.sql = sql
self.table = table
self.redshift = PostgresHook(postgres_conn_id=redshift_conn_id)
self.append = append
def execute(self, context):
if not self.append:
self.log.info("Clearing data from destination Redshift Fact table")
self.redshift.run("DELETE FROM {}".format(self.table))
self.log.info("Load data to Redshift Fact table")
self.redshift.run(self.sql)
Data Quality Operator
The final operator to create is the data quality operator, which is used to run checks on the data itself. The operator’s main functionality is to receive one or more SQL based test cases along with the expected results and execute the tests. For each the test, the test result and expected result needs to be checked and if there is no match, the operator should raise an exception and the task should retry and fail eventually.
For example one test could be a SQL statement that checks if certain column contains NULL values by counting all the rows that have NULL in the column. We do not want to have any NULLs so expected result would be 0 and the test would compare the SQL statement’s outcome to the expected result.
class DataQualityOperator(BaseOperator):
ui_color = '#89DA59'
@apply_defaults
def __init__(self,
redshift_conn_id="",
table="",
sql="",
*args, **kwargs):
super(DataQualityOperator, self).__init__(*args, **kwargs)
self.sql = sql
self.table = table
self.redshift = PostgresHook(postgres_conn_id=redshift_conn_id)
def execute(self, context):
records = self.redshift.get_records(self.sql)
if len(records) < 1 or len(records[0]) < 1:
raise ValueError(f"Data quality check failed. {self.table} returned no results")
num_records = records[0][0]
if num_records > 1:
raise ValueError(f"Data quality check failed. {self.table} contained {num_records} rows")
4. Check result
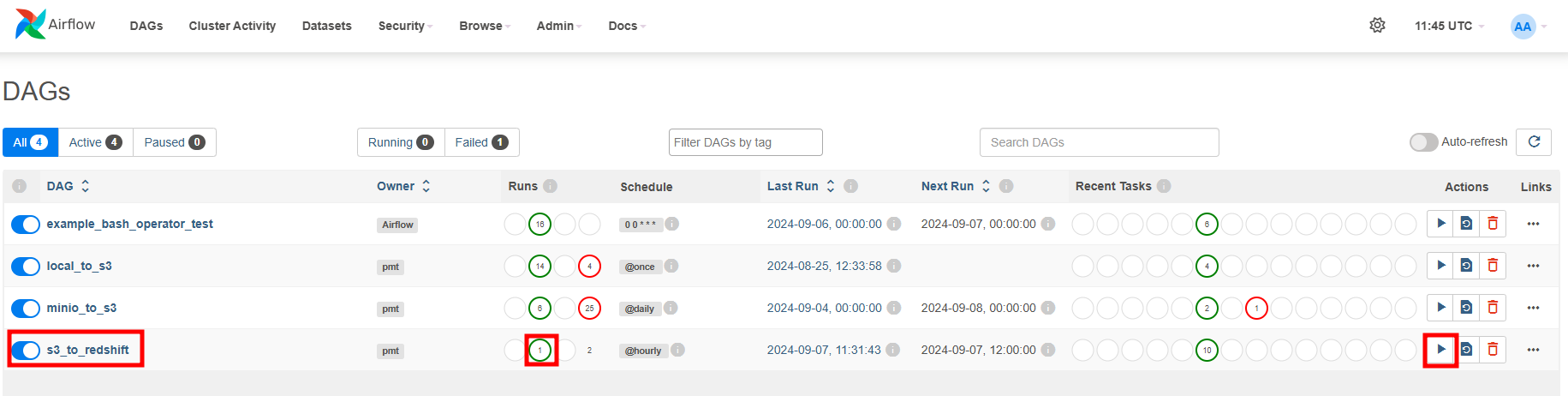
Upload DAG, plugins.zip to S3 bucket of MWAA
Check DAG on Airflow UI
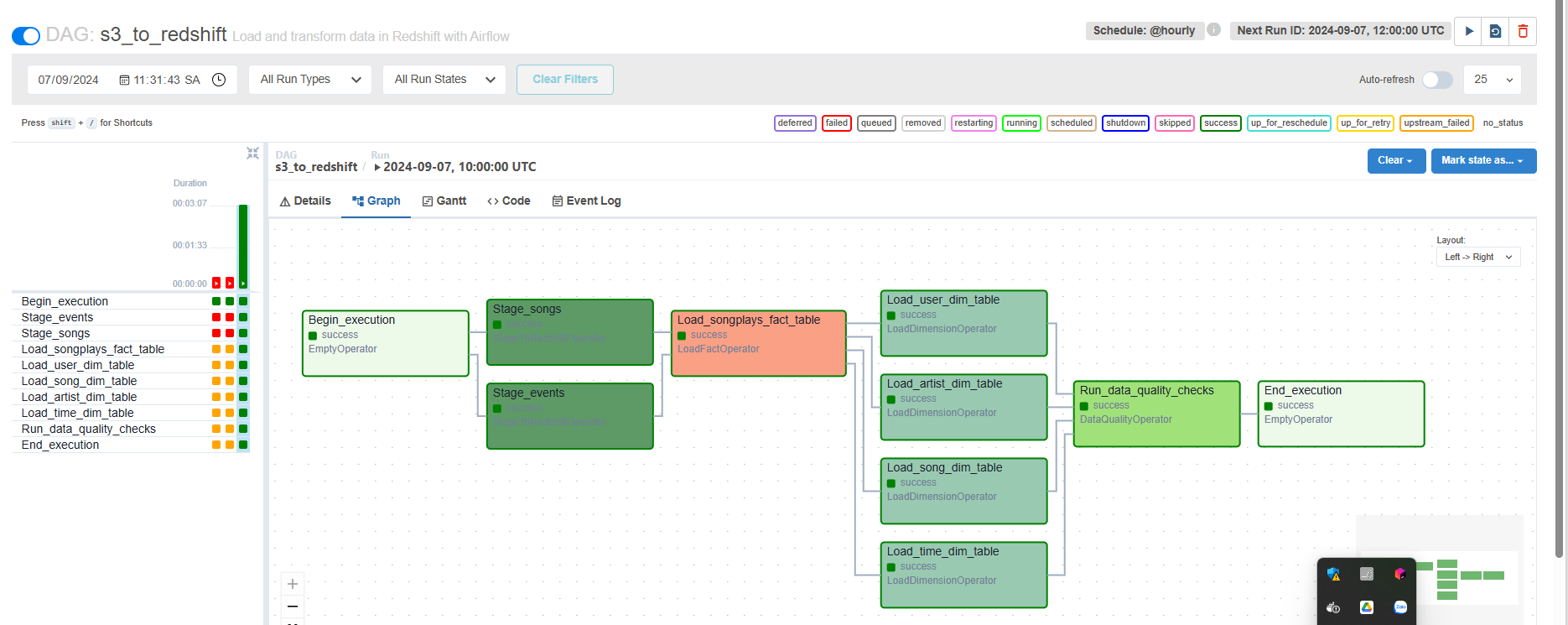
Run DAG
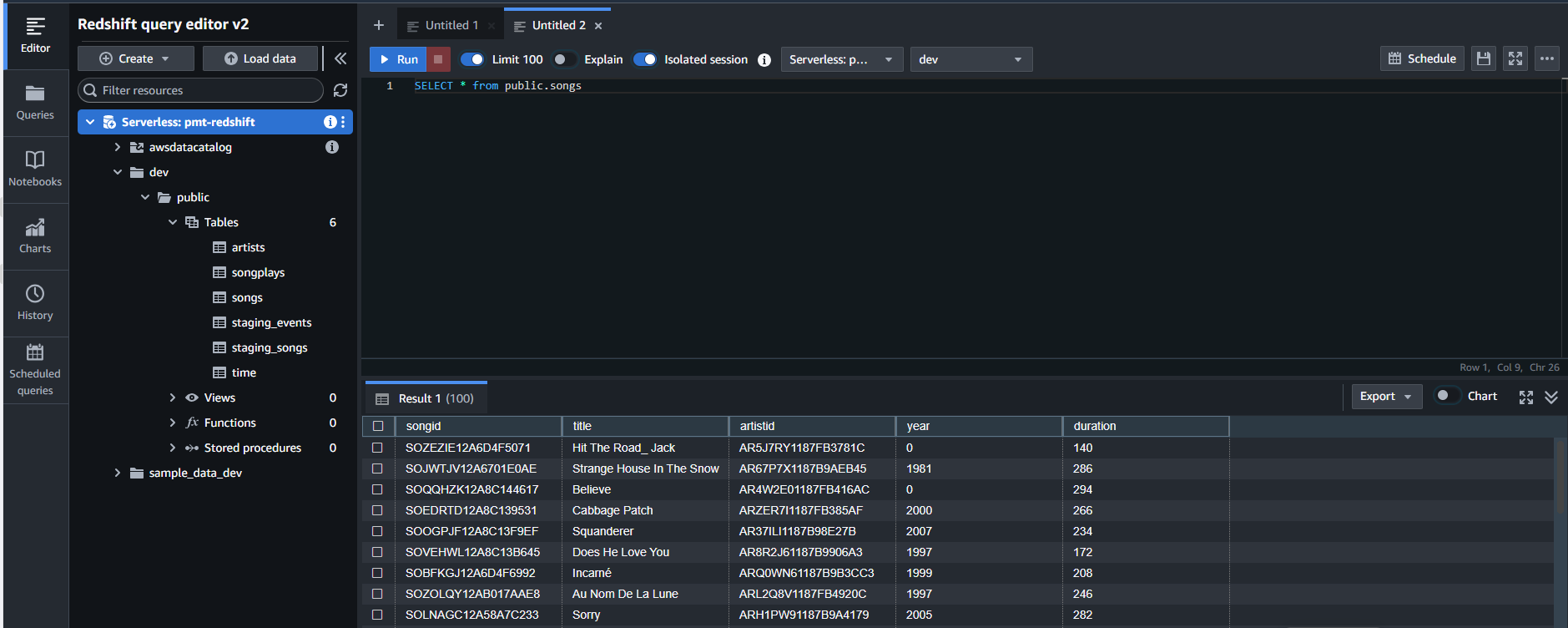
Access Redshift UI and query
5. Clean up
Delete Environment MWAA
Delete Redshift
Delete IAM role
Delete Workgroups