AWS Serverless Data Lake Jumpstart
Overview
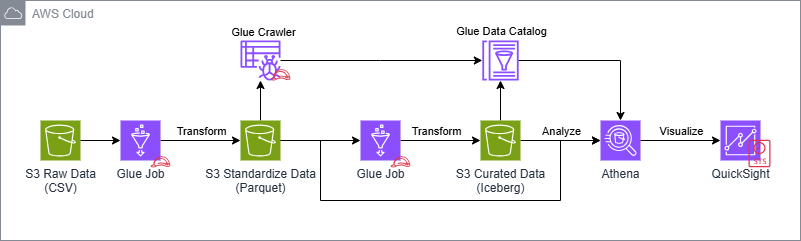
This workshop is prepared to guide participants on how to use AWS serverless services to build a cloud-native and future-proof serverless data lake architecture. We will use AWS Glue for ETL and data catalog management, Amazon S3 for data lake storage, Amazon Athena to query data and Amazon QuickSight to visualize data.
Objective
The objective of the workshop is to enable participants to jumpstart their journey of building a serverless data lake using the Lambda Architecture data-processing design pattern. Participants will go through a series of guided hands-on lab exercise using AWS serverless services to build a solution and tackle real-world scenarios.
Target Audience
This course is intended for Data Architects, Data Engineers, ETL Developers, BI Developers and other data practitioners.
We recommend that attendees of this workshop have working knowledge of database concepts and basic understanding of data storage, processing, and analytics.