Preparing and Cataloging your Data
Overview
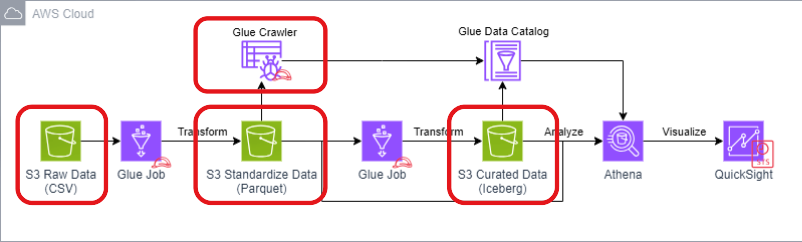
With an array of data sources and formats in your data lake, it’s important to have the ability to discover and catalog it order to better understand the data that you have and at the same time enable integration with other purpose-built AWS analytics.
In this lab, we will create an AWS Glue Crawlers to auto discover the schema of the data stored in Amazon S3. The discovered information about the data stored in S3 will be registered in the AWS Glue Catalog. This allows AWS Glue to use the information stored in the catalog for ETL processing. It also allows other AWS services like Amazon Athena to run queries on the data stored in Amazon S3.