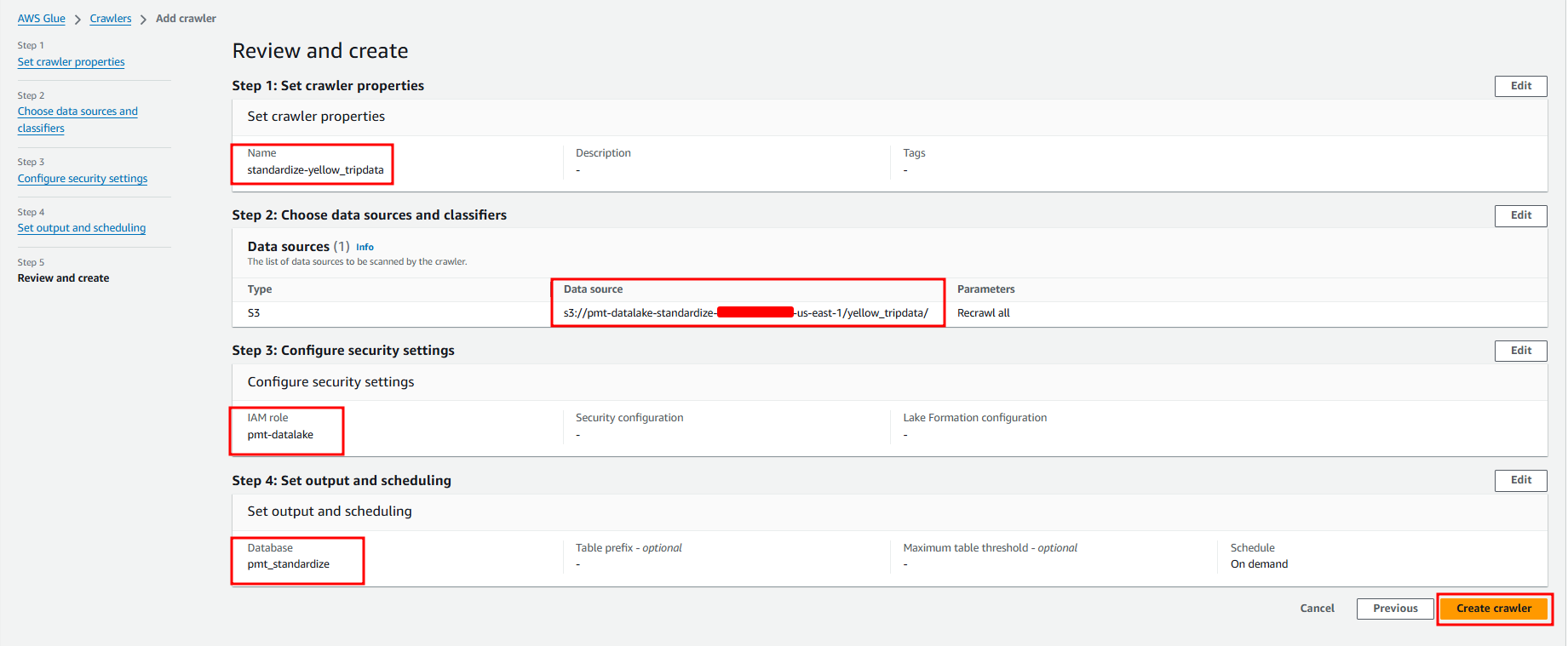
Create Crawler
Glue Crawler is a feature that automatically infer database and table schema from your source data then stores the associated metadata in the AWS Glue Data Catalog.
Create Crawler for taxi_zone_lookup table
Go to the AWS Glue Console.
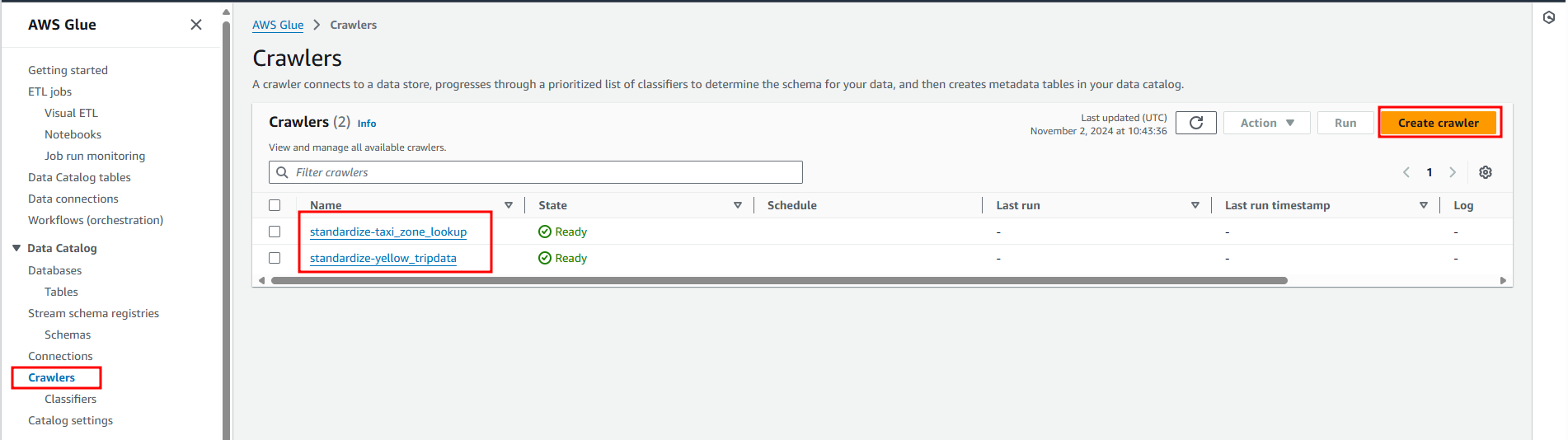
In the left navigation menu, click Crawlers.
On the Crawlers page, click Create a crawler.
Specify crawler’s name, click Next.
On the Choose data sources and classifiers screen, specify the following information, and then click Next.
- Click Add a data source
- Choose a Data source – S3
- Select Location of S3 data - In this account
- Include S3 path – s3://{Standardize_BUCKET}/taxi_zone_lookup/
- For Subsequent crawler runs, select to Crawl all sub-folders
- Then click Add an S3 data source.
On Configure security settings, choose your datalake role from the Existing IAM role, click Next.
Choose your Standardize database.
On the Crawler schedule, leave the frequency On demand, click Next.
Review the crawler details, click Create crawler.
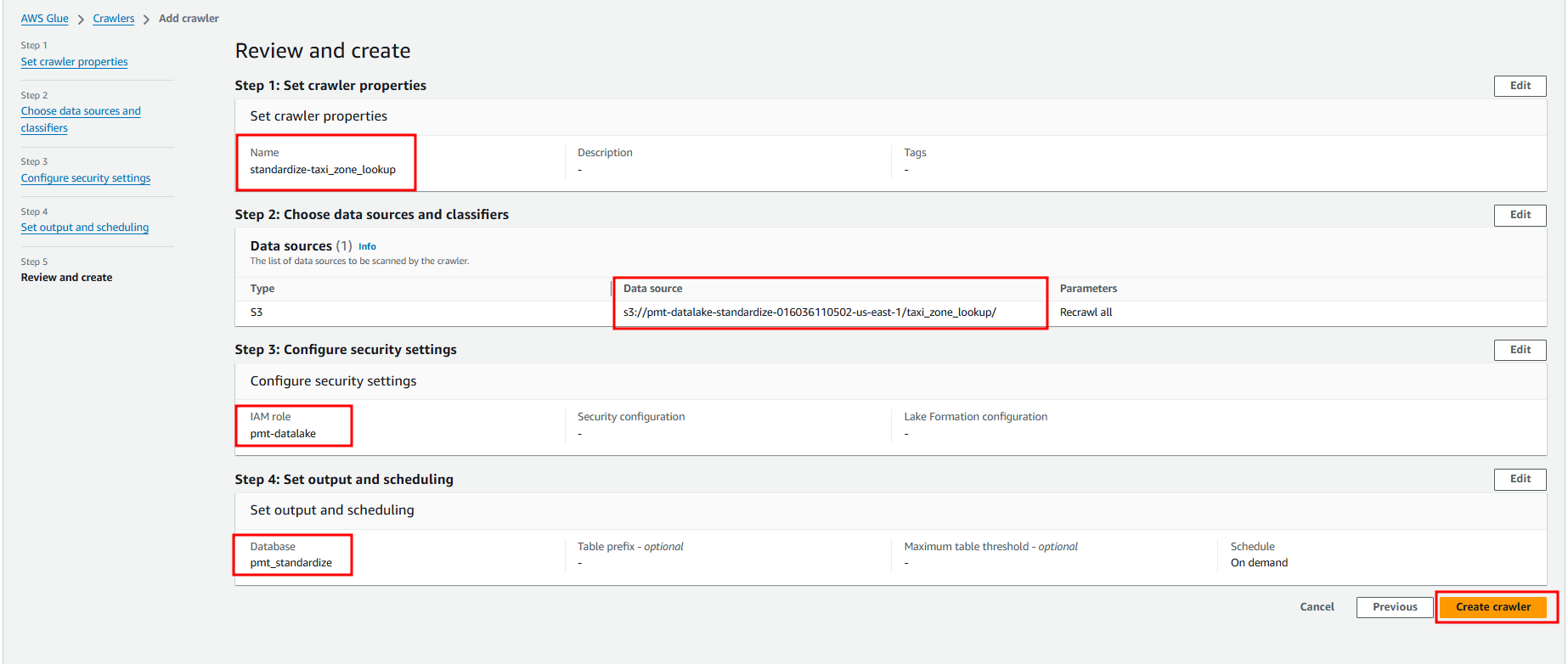
Create Crawler for yellow_tripdata table
Go to the AWS Glue Console.
In the left navigation menu, click Crawlers.
On the Crawlers page, click Create a crawler.
Specify crawler’s name, click Next.
On the Choose data sources and classifiers screen, specify the following information, and then click Next.
- Click Add a data source
- Choose a Data source – S3
- Select Location of S3 data - In this account
- Include S3 path – s3://{Standardize_BUCKET}/yellow_tripdata/
- For Subsequent crawler runs, select to Crawl all sub-folders
- Then click Add an S3 data source.
On Configure security settings, choose your datalake role from the Existing IAM role, click Next.
Choose your Standardize database.
On the Crawler schedule, leave the frequency On demand, click Next.
Review the crawler details, click Create crawler.